

Exploring Single Point Failures: Causes and Impacts
Introduction
Exploring Single Point Failure, also known as a single point of failure (SPOF), refers to a component, system, or process within a larger system that, if it fails, can cause the entire system to fail or significantly impair its operation. In other words, a single point failure is a vulnerability that can lead to a complete breakdown or loss of functionality in a system and way to Preventing Single Point Failures.
What is?
The term “single point” implies that there is a solitary weak link in the system that, if disrupted, can have a cascading effect on the entire system’s performance. This weak link can be a hardware component, software component, network connection, power supply, or any other critical element. The failure of this component can disrupt the normal operation of the system and render it inoperable or cause it to malfunction.
Single point failures are undesirable in critical systems because they lack redundancy or alternative paths for operation. The absence of redundancy means that there is no backup or failover mechanism to compensate for the failure, increasing the risk of system-wide failure or prolonged downtime. Consequently, single point failures are a significant concern in areas such as transportation systems, data centers, telecommunications networks, and other vital infrastructures where system reliability and uptime are crucial.
To mitigate the risks associated with single point failures, system designers and engineers employ redundancy strategies, fault-tolerant designs, backup systems, and other measures to ensure that if one component fails, there are alternative mechanisms in place to maintain system operation. Reducing or eliminating single points of failure is an essential consideration in building robust and reliable systems.

What causes Single point failures?
Lack of Redundancy: When a critical component or system does not have redundant backups or alternative pathways, it becomes a single point of failure. If that component fails, there is no backup mechanism to take over its function, resulting in a system failure.
Design Flaws: Poor system design can introduce single points of failure. For example, if a system relies on a single power supply, and that power supply fails, the entire system may go down. Inadequate redundancy planning or failure to consider potential failure points during the design phase can lead to single point failures.
Insufficient Maintenance: Neglecting regular maintenance and inspections can increase the likelihood of single point failures. Components may degrade over time, become more prone to failure, or have critical issues that go unnoticed without proper maintenance practices. Failure to identify and address these issues can lead to unexpected failures.
Environmental Factors: Environmental conditions such as temperature, humidity, vibrations, or power fluctuations can contribute to single point failures. If a critical component is exposed to extreme conditions or subjected to environmental stresses, it may fail and disrupt the overall system.
Human Error: Human errors, such as incorrect configuration, improper handling of equipment, or accidental damage to critical components, can introduce single points of failure. Mistakes during installation, maintenance, or operation can inadvertently create vulnerabilities in the system.
Software or Firmware Issues: Bugs, vulnerabilities, or compatibility issues in software or firmware can also result in single point failures. If a critical software component or firmware module fails or malfunctions, it can affect the entire system’s functionality.
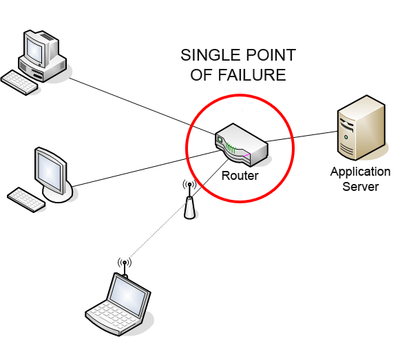
How to Avoid SPF?
To avoid single point failures, you can follow these guidelines:
Identify Critical Components: Identify the critical components, systems, or processes that, if failed, would have a significant impact on the overall operation or functionality of your system. These are the areas where you need to focus on eliminating single points of failure.
Redundancy Planning: Implement redundancy by having backup systems, components, or processes in place. Ensure that there are alternative pathways or redundant backups that can take over if a failure occurs. Redundancy can be achieved through duplicate hardware, mirrored systems, backup power supplies, or multiple network connections.
Diverse Pathways: Design systems with diverse pathways to minimize the reliance on a single route. For example, if you have critical network connections, ensure there are multiple independent routes available to avoid a single point of failure in the network infrastructure.
Fault-Tolerant Design: Incorporate fault-tolerant design principles into your system architecture. This includes building in mechanisms that can detect failures and automatically switch to alternative components or systems, minimizing the impact of a single point failure.
Regular Maintenance and Inspections: Implement a comprehensive maintenance program that includes regular inspections, testing, and proactive replacement of aging or degraded components. By identifying and addressing potential failure points, you can prevent single point failures before they occur.
Environmental Controls: Ensure that critical components are protected from extreme environmental conditions such as temperature, humidity, and power fluctuations. Implement environmental controls and monitoring systems to minimize the risk of failures caused by adverse conditions.
Robust Monitoring: Implement a robust monitoring system that constantly tracks the health and performance of critical components. This enables early detection of potential failures, allowing you to take preventive action before they escalate into single point failures.
Training and Documentation: Provide comprehensive training to system operators and users on proper operation, maintenance, and troubleshooting procedures. Well-documented processes and procedures help minimize human errors that can lead to single point failures.
Regular Testing and Simulation: Conduct regular testing and simulations to identify vulnerabilities and assess the resilience of your system. Simulate failure scenarios and evaluate the system’s response to ensure it can withstand single point failures.
Continual Improvement: Regularly review and improve your system design and processes based on lessons learned from past failures or near-misses. Continuously assess and update your strategies to avoid single point failures.
Happy Coding 🙂

